
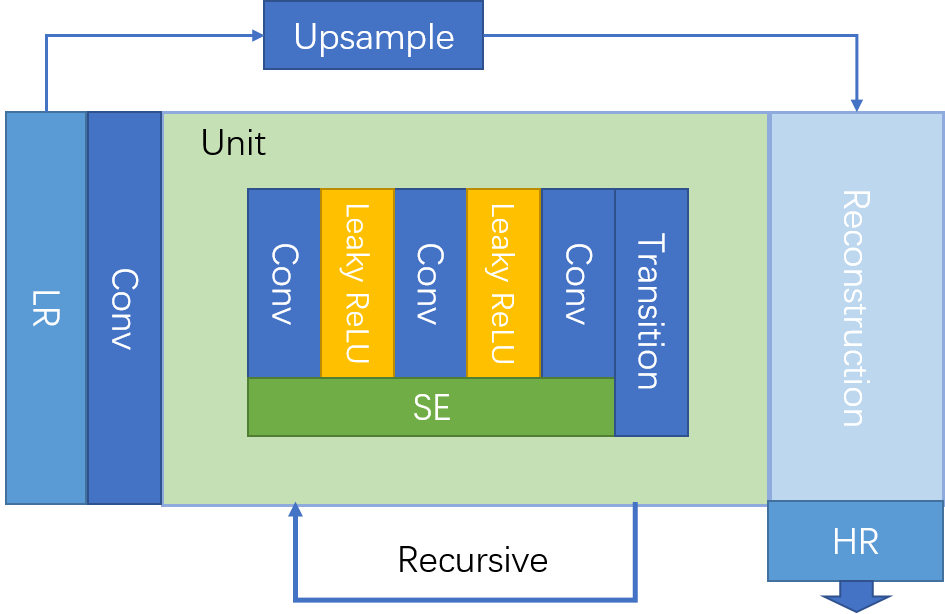
SESR是我在ICPR2018上投稿的一篇文章。
之所以称它高效,是应为这个模型的每个branch上只递归了4次,如果换算成堆叠的式的,也总共只有24层,再加上头尾以及做上采样的三个卷积,每个分支总共只有27层。其中SE模块和过渡卷积都是1x1的kernel,如果把x2和x4两个branch都算上,整体参数数量其实只有624k
对比一下其他的模型,比如84层的MemNet,PSNR和SSIM均有所超越,所以说效率其实还是相当高的
| Method | PSNR/SSIM | |||
| Set5 | Set14 | Bsd100 | Urban100 | |
| Bicubic | 28.43/0.811 | 26.01/ 0.704 | 25.97/ 0.670 | 23.15/ 0.660 |
| A+ [6] | 30.32/ 0.860 | 27.34/ 0.751 | 26.83/ 0.711 | 24.34/ 0.721 |
| SRCNN [12] | 30.50/ 0.863 | 27.52/ 0.753 | 26.91/ 0.712 | 24.53/ 0.725 |
| FSRCNN [33] | 30.72/ 0.866 | 27.61/ 0.755 | 26.98/ 0.715 | 24.62/ 0.728 |
| SelfExSR [8] | 30.34/ 0.862 | 27.41/ 0.753 | 26.84/ 0.713 | 24.83/ 0.740 |
| VDSR [15] | 31.35/ 0.883 | 28.02/ 0.768 | 27.29/ 0.726 | 25.18/ 0.754 |
| DRCN [16] | 31.54/ 0.884 | 28.03/ 0.768 | 27.24/ 0.725 | 25.14/ 0.752 |
| LapSRN [17] | 31.54/ 0.885 | 28.19/ 0.772 | 27.32/ 0.727 | 25.21/ 0.756 |
| DRRN [2] | 31.68/ 0.888 | 28.21/ 0.772 | 27.38/ 0.728 | 25.44/ 0.764 |
| SESR(ours) | 31.84/ 0.891 | 28.32/ 0.784 | 27.42/ 0.737 | 25.42/ 0.771 |

配套代码:GitHub
Comments 1 条评论
第二段开头有错别字(只能挑错别字的小白,嘿嘿),应该是“因为”