
2.原理简述
Alpha Go与之前的其他围棋AI的差别并没有我们想象中的大,他们都是基于Monte-Carlo Search的。对于所有的游戏,其可能发生的情况有种,其中b是宽度,即每个位置,d是深度,即游戏进行的回合数,由于情况太多,模拟出所有可能发生的情况几乎是不可能的。Alpha Go中存在价值网络(value network)和决策网络(policy network),其中,价值网络通过查找树的本节点s的子节点a做出预测,以近似价值选项来替代最佳价值选项,并顺着这个树的子节点进一步分析子节点的下一层,执行了若干次之后,将每一次的成功率返回,从而整合出节点s的胜率,其次,可以通过以s条件下a的概率分布进一步简化问题,使用蒙特卡洛查找方法,通过决策p对双方操作序列进行抽样,从而不需要过多的分支树,对输出结果取平均即可获得一个比较有效的位置评价。在此方法下AI可以有效地减少低级错误的发生。
正因为有蒙特卡洛查找,所有采用这个算法的计算机都可以有效地评价查找树的每一步的胜率,简言之,就是全局意识比人类要强,一般的棋手是通过经验来分析盘面,而机器的优势在于对于整个盘面进行具体的,细节的评估。相较于Alpha Go,之前的人工智能系统虽然也采用了MCTS,但是他们对决策的分析通常是渐层的,价值选项也只是通过对输入产生的简单线性组合。
蒙特卡洛树搜索(MCTS)简言之可以分为四个步骤,即1.选择,2.拓展,3.模拟与4.反向传播。第一步选择就是从当前状态s选择一个子节点a1进行拓展,首先系统需要检查s状态是否存在一个没有被评估过的操作f1,如果存在,则对a1进行扩展,如果不存在,则通过UCB公式运算出一个拥有最大UCB值的操作,并且对于操作后产生的状态a2再次进行检查,以此类推进行循环操作,如果状态an是一个游戏结束的状态,此时进行步骤4,如果状态an依旧存在一个没有被评估过的操作fn,则进行步骤2对子状态进行拓展。拓展即对于待拓展的状态添加一个子节点a,这个节点是由该状态通过未评估操作f产生的,拓展完成后即进行第三步模拟。模拟过程是通过蒙特卡洛方法,模拟随机落子,并继续通过子状态循环分析,最终得到结果,并更新该节点的胜率。步骤4反向传播简言之就是在模拟结束之后,从底层节点按照生成路径依次更新父节点以及各个祖先节点的平均胜率。通过对这四个步骤的迭代,每走一步系统都会更新该步骤的胜率,以及预测下一步胜率高的落子点,并由此衍生出了价值网络和决策网络。
近几年深度卷积神经网络(deep convolutional neural networks)的发展十分迅速,在模式识别和其他方面得到了广泛的应用,而这类富含神经元的架构也被运用在了Alpha Go当中。Google的研究人员通过对职业棋手的棋谱和self-play对机进行训练。其中,通过SL(supervised learning)网络,模拟学习人类的行为,此外,还有快速走子(因为围棋中落子有时间限制),第三还要训练一个RL(reinforcement learning)网络,此训练主要通过优化self-play的结果而进行。通过这些学习行为,AI可以朝着赢得比赛的正确方向做出决策,Google将其整合成为了一个价值网络(value network),并与蒙特卡洛查找(MCTS)结合,Alpha Go相比之前的所有系统显得格外的强大。
图1 SL示意图
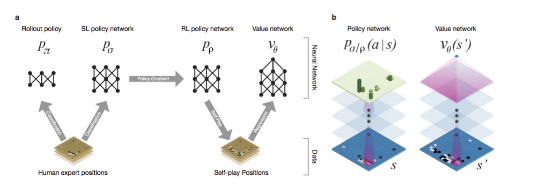
图2 RL优化后的示意图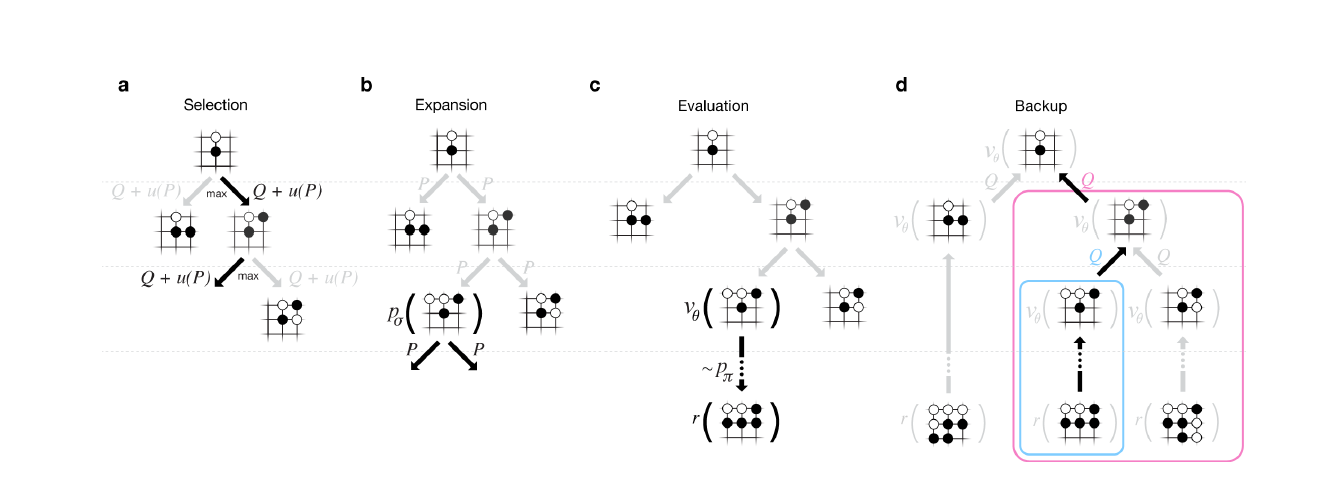
图3 a:Alpha Go与其他围棋AI对比 b:不同网络效果对比 c:GPU列阵数效果对比
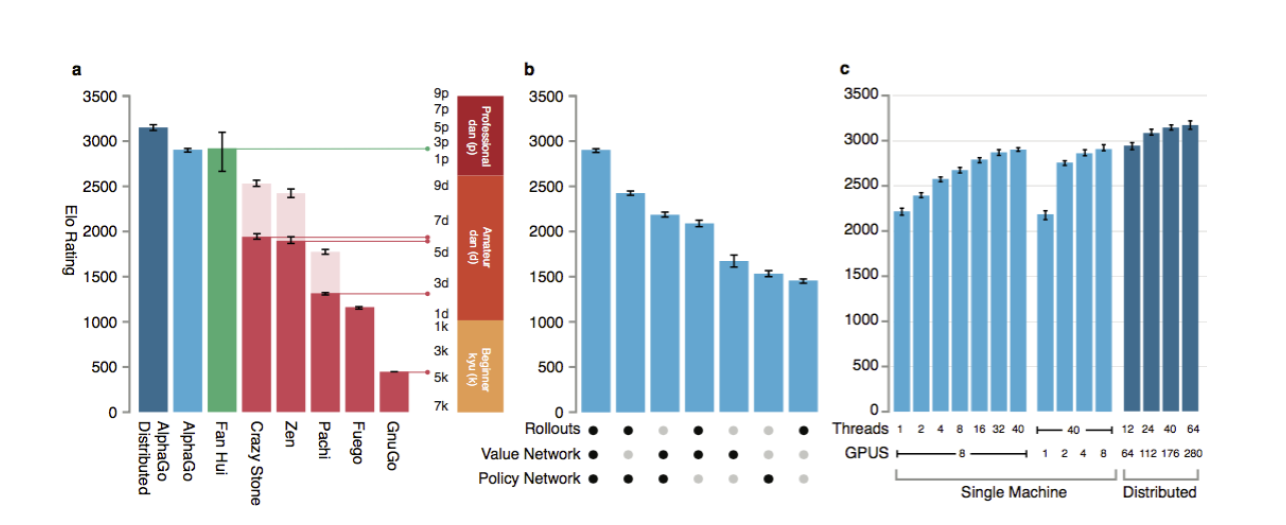
*图片均来自于Mastering the game of Go with deep neural networks and tree search
3.总结与预测
总的来说,Alpha Go在于对手的五局比赛中取得了骄人的成绩,但是从第四局的失利来看,整个系统仍旧存在一些bug,这些bug是由研究人员在编程的时候产生的,通过机器再多次的学习也无法弥补。其次,AlphaGo在细节上仍然存在一些不完善的地方:比如在某一节点,机器确定自己可以获胜,走哪一步都能赢,则下一步的选择便会不受价值网络的控制直接快速走子,有可能会造出局部的丢分。
不可否认,人工智能是未来发展的一大趋势,Alpha Go虽然只是专门针对于围棋的一个AI但是它背后的原理可以为更多的领域服务,我们应该以开放的态度对待人工智能的发展,共同期待人工智能高度发达的未来。
Comments NOTHING